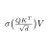
Debugging
Medium
@danielhanchen
Importance score: 4 • Posted: March 09, 2026 at 21:46
Score
4
If you find Claude Code with local models to be 90% slower, it's because CC prepends some attribution headers, and this changes per message causing it to invalidate the entire prompt cache / KV cache. So generation becomes O(N^2) not O(N) for LLMs.

Note: Claude Code invalidates the KV cache for local models by prepending some IDs, making inference 90% slower. See how to fix it here: https://unsloth.ai/docs/basics/claude-code#fixing-90-slower-inference-in-claude-code https://x.com/UnslothAI/status/2031123848729600371/photo/1

Grok reasoning
Practical fix for performance issue in Claude Code with local models, from Unsloth AI founder, useful for developers.
Likes
881
Reposts
72
Views
93,505
Tweet ID: 2031124589557002457
Prompt source: ai-news
Fetched at: March 10, 2026 at 06:02