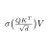
Daniel Han
@danielhanchen
If you find Claude Code with local models to be 90% slower, it's because CC prepends some attribution headers, and this changes per message causing it to invalidate the entire prompt cache / KV cache. So generation becomes O(N^2) not O(N) for LLMs.

Unsloth AI
@UnslothAI
· Mar 9
Note: Claude Code invalidates the KV cache for local models by prepending some IDs, making inference 90% slower. See how to fix it here: unsloth.ai
