Wildminder
@wildmindai
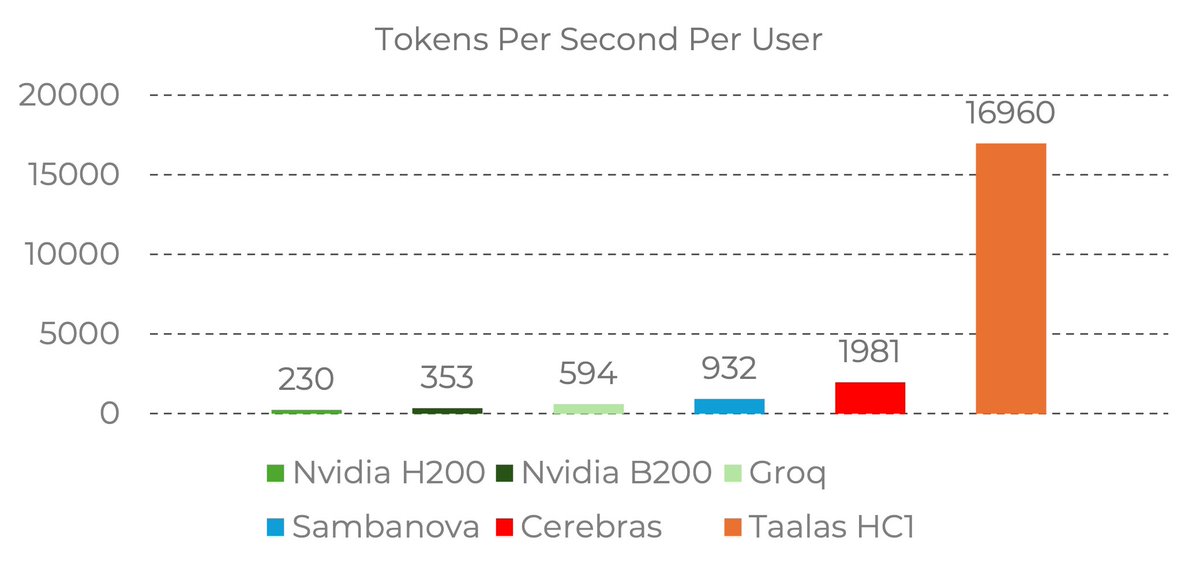
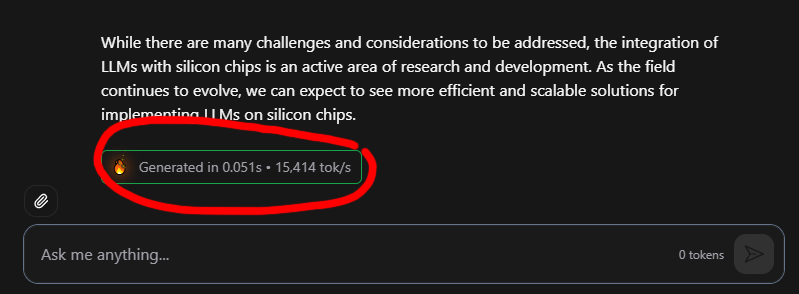
17,000 tokens per second!! Read that again! LLM is hard-wired directly into silicon. no HBM, no liquid cooling, just raw specialized hardware. 10x faster and 20x cheaper than a B200. the "waiting for the LLM to think" era is dead. Code generates at the speed of human thought. Transition from brute-force GPU clusters to actual AI appliances.