
Nathan Hu
@NathanHu12
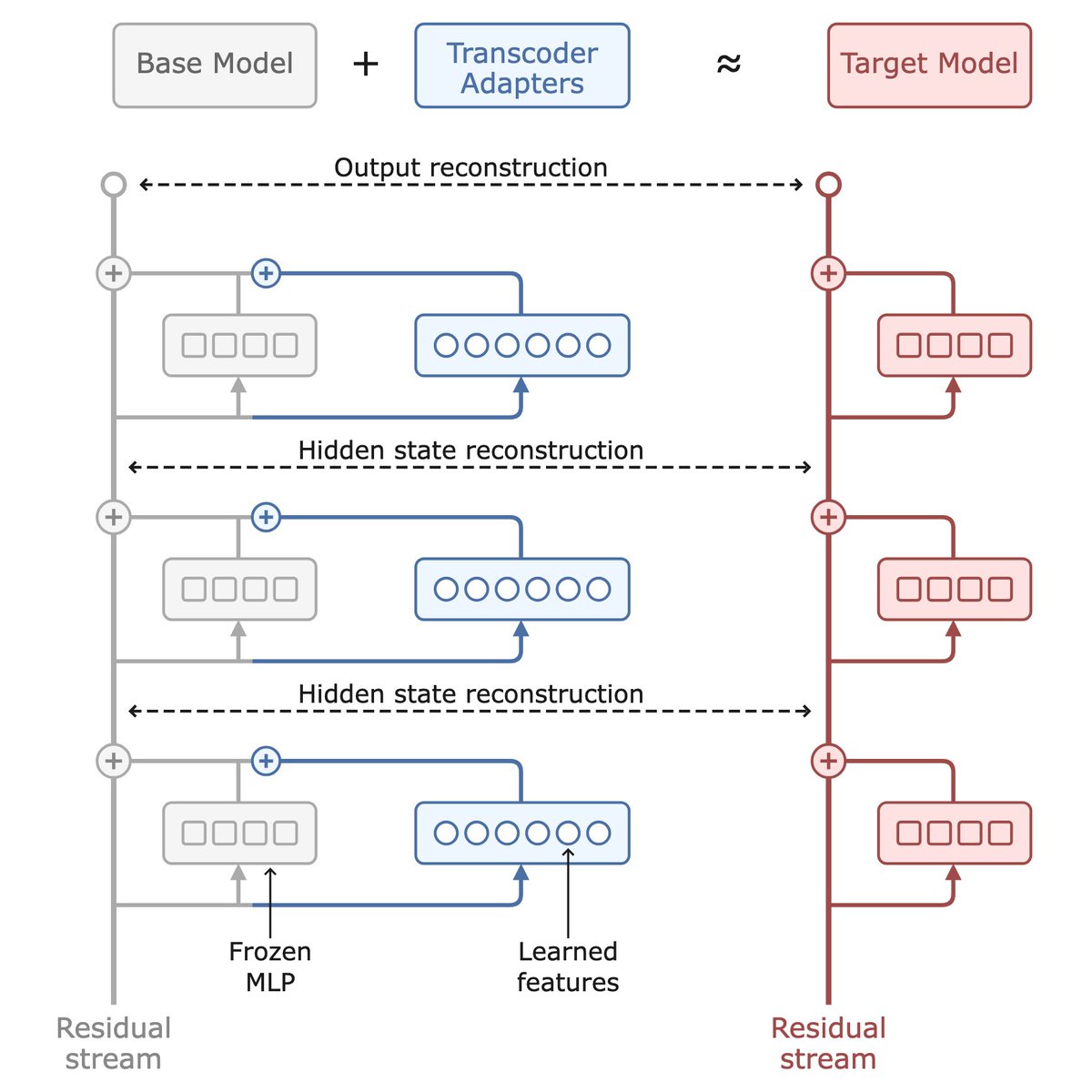
What does reasoning fine-tuning actually change inside a model? In our new paper, we introduce transcoder adapters to learn sparse, interpretable approximations of how reasoning fine-tuning changes MLP computation. 🧵
@NathanHu12
What does reasoning fine-tuning actually change inside a model? In our new paper, we introduce transcoder adapters to learn sparse, interpretable approximations of how reasoning fine-tuning changes MLP computation. 🧵