Sumanth
@Sumanth_077
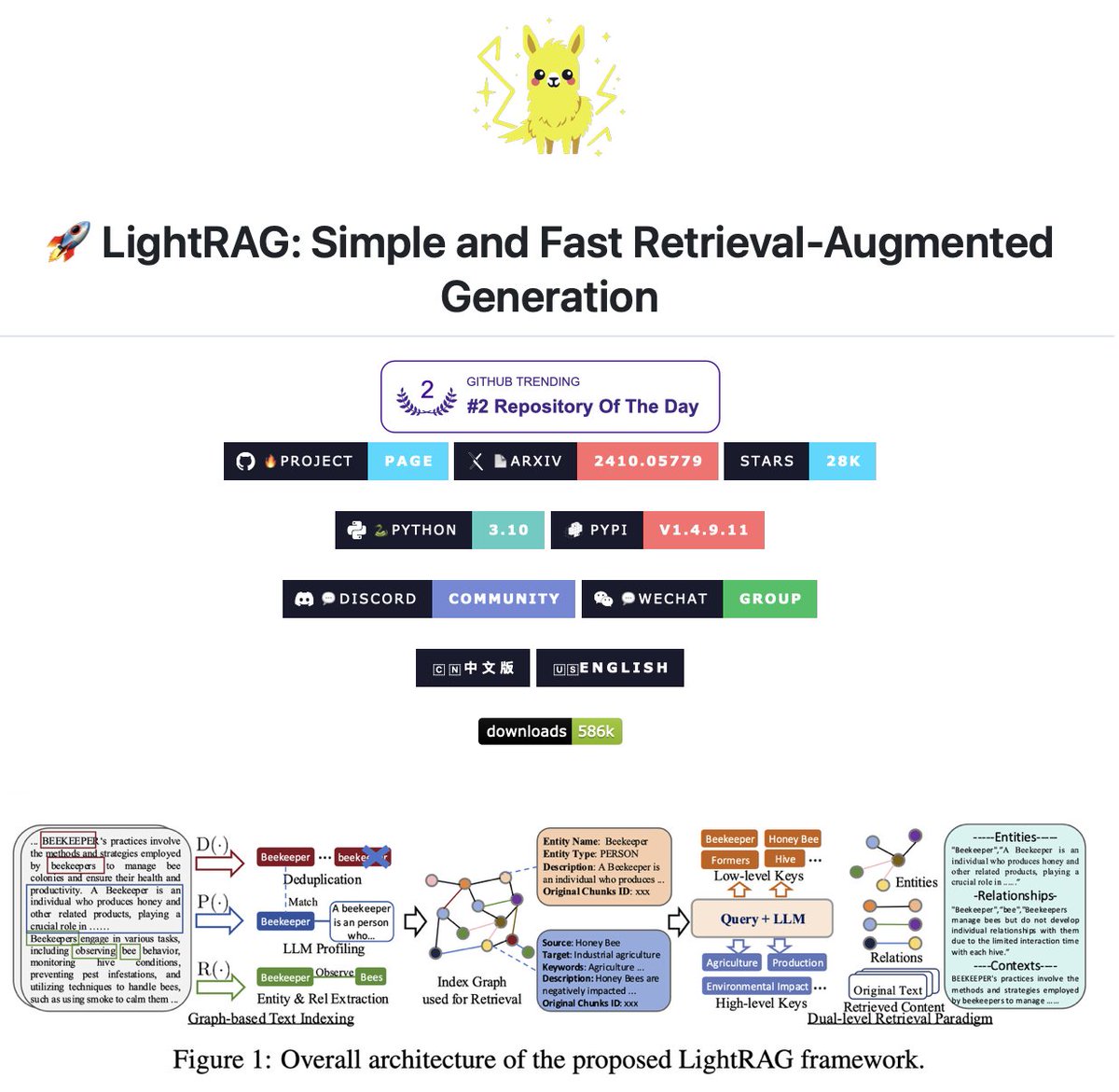
Graph-based RAG with dual-level retrieval! LightRAG is an open-source RAG framework that builds knowledge graphs from documents and uses dual-level retrieval to answer both specific and conceptual queries. Traditional RAG relies on vector similarity and flat chunks. This works for shallow lookups but fails when queries require understanding how concepts connect. LightRAG solves this by extracting entities and relationships to build structured knowledge graphs. It uses LLMs to identify entities (people, places, events) and their relationships from documents, then constructs a comprehensive knowledge graph that preserves these connections. The framework uses dual-level retrieval: Low-level retrieval targets specific entities and details (e.g., "What is Mechazilla?") High-level retrieval aggregates information across multiple entities for broader questions (e.g., "How does Elon Musk's vision promote sustainability?") For each query, LightRAG extracts both local and global keywords, matches them to graph nodes using vector similarity, and gathers one-hop neighboring nodes for richer context. What makes it different: • Graph-based indexing preserves relationships between concepts instead of treating information as isolated fragments • Dual-level retrieval handles both specific lookups and conceptual queries • Automatic entity extraction without manual annotation • Incremental updates add new information without full rebuilds • Multimodal support integrates with RAG-Anything for PDFs, Office docs, images, tables, and formulas Key Features: - Knowledge graph visualization through WebUI - Multiple storage backends (PostgreSQL, Neo4j, MongoDB, Qdrant) - Supports major LLM providers (OpenAI, Anthropic, Ollama, Azure) - Reranker support for mixed queries - Document deletion with automatic KG regeneration It's 100% open source. Link to the repo in the comments!