DailyPapers
@HuggingPapers
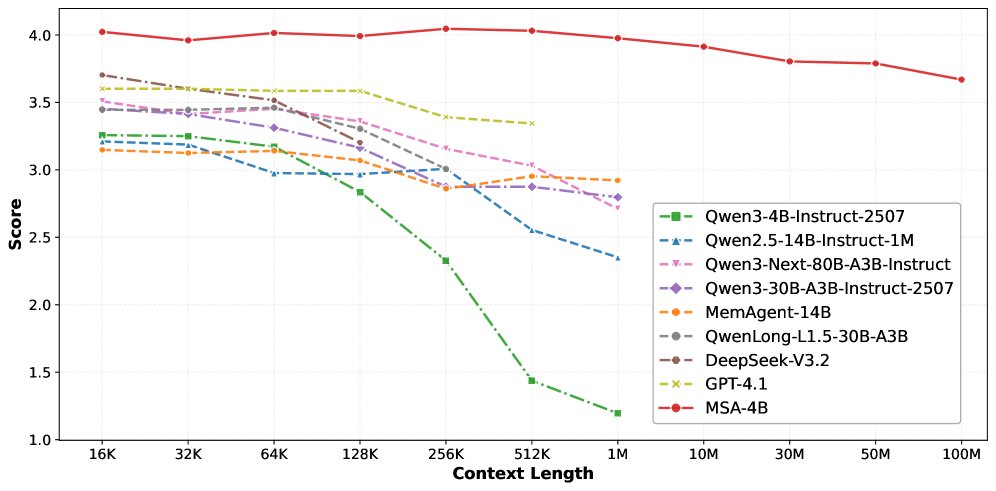
MSA breaks the 100M token barrier Memory Sparse Attention achieves unprecedented 100M token context lengths with near-linear complexity. The architecture maintains 94% accuracy at 1M tokens while outperforming RAG systems and frontier models, using end-to-end sparse attention with document-wise RoPE.